Sintaxe, Semântica, Contexto e Densidade de Informação
Jonas Abreu em 10/09/2013TL;DR:
Código legível
Eu passei os últimos dois anos fazendo experiências sobre como ensinar design de código Java. Um dos pontos que sempre tive que explicar (e que era sempre meio difícil de entender) é o que torna um código legível.
Depois de olhar bem para as respostas (e as perguntas) dos meus alunos, notei que o que eu classificava como legível era um equilíbrio (subjetivo) entre quatro propriedades do código. Sintaxe, Semântica, Contexto e Densidade da informação.
Sintaxe
Sintaxe todo programador conhece. É o que o compilador reclama quando falta:

E o que nos atrapalha muito quando sobra:

A parte de faltar sintaxe, no fim das contas nunca é um problema. Porque simplesmente não funciona. O problema é quando sobra tanta sintaxe quanto no exemplo. A quantidade de coisas que ficam no meio do caminho do que você quer lêr (O que aquele código realmente faz) é um problema.
Obviamente o exemplo é uma das piores formas de se escrever aquele código (Não usar classes anônimas de Java já ajudaria bastante), mas esse é exatamente o ponto. A sintaxe te força a escrever o código de uma forma e te atrapalha se você tentar escrever de outra. Equilibrar esses dois pontos não é tão trivial quanto fazer o compilador entender o código.
Semântica
Olhando para a semântica do código, existem sempre dois alvos fortes da nossa comunicação. Um é o compilador, para o qual não faz a menor diferença os nomes que damos:
Um código como:

O compilador vê como:

Ele simplesmente usa os nomes que damos como identificadores e depois joga no lixo. Ele não entende essa informação semântica. E faz bem, porque ela não está ali para ele. Nós colocamos ela para seres humanos que vão ler o código.
O grande problema é que muitas vezes não damos atenção à essa informação que temos que colocar para humanos e acabamos escrevendo código assim:

E então é a nossa cabeça que agora tem que fazer o processo do compilador e ainda adivinhar a informação semântica que não está presente.

Além de ser cansativo, em geral a gente tem outras coisas na cabeça e fica ainda mais difícil manter o foco.
Contexto
Quando falamos sobre contexto, associado à linguagens de programação, a primeira coisa que nos vem à cabeça são as liguagens livres de contexto:
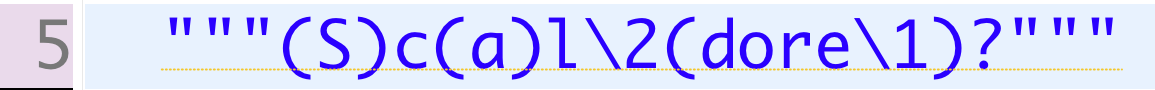
Um exemplo de linguagem livre de contexto são as expressões regulares. Outro exemplo são quase todas as outras linguagens de programação que conhecemos, como Java, Scala, C#, C, Ruby, Python, etc.
Mas isso é o contexto sintático da linguagem (uma linguagem livre de contexto é uma linguagem que pode ser gerada por uma gramática livre de contexto). Quando falamos sobre contexto semântico, a coisa muda de figura porque o significado das palavras que usamos para descrever o que o código faz é completamente dependente do contexto onde está inserido.
Gaste alguns segundos tentando entender o seguinte código:

Difícil correto? A não ser que você tenha escrito esse algoritmo muitas vezes, fica complicado de saber o que faz. Vamos acrescentar um pouco de informação:
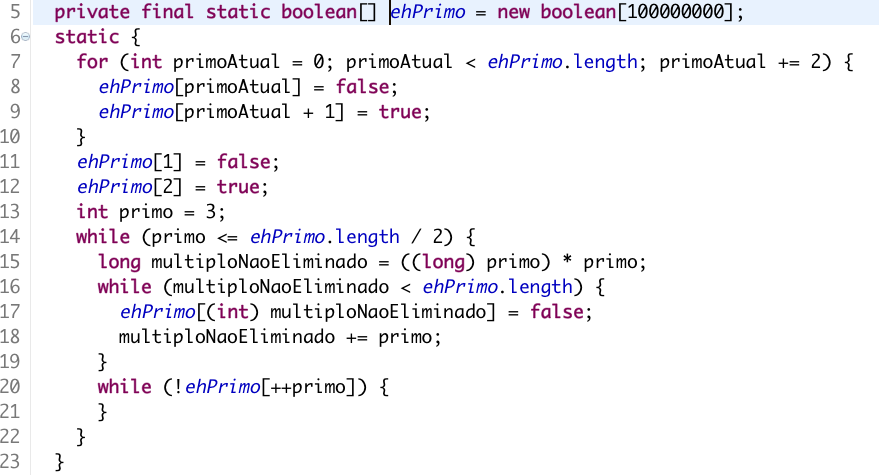
Facilitou um bocado. Agora provavelmente você já sabe que esse algorítmo carrega um vetor boolean que diz se o elemento daquela posição é um número primo ou não. Mas provavelmente você ainda não sabe qual é o algorítmo usado e é bem difícil dizer se um código como esse está certo sem saber qual é o algorítmo. Vamos acrescentar um pouco de contexto então:
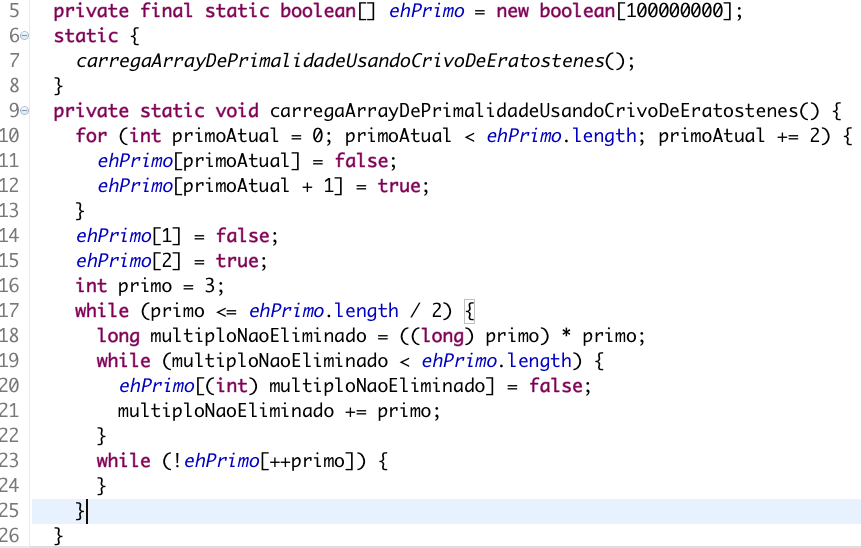
Agora com uma simples busca no google, você encontra a página da wikipedia que descreve o Crivo de Eratóstenes. Inclusive tem um gif para facilitar o entendimento dele.
Então ter bastante contexto ajuda? Não necessáriamente. Muito contexto pode ser um problema também. Dêem uma olhada no seguinte código:
O nome do método não está incluso de propósito.
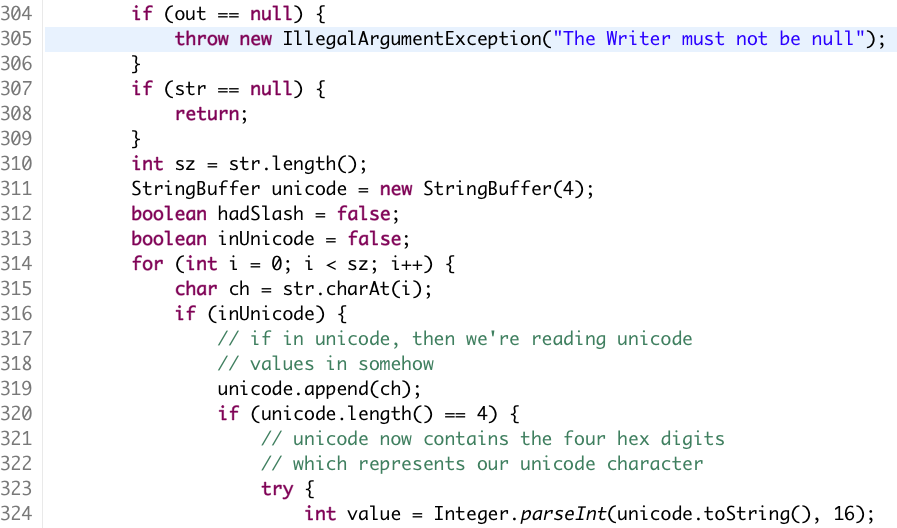
Já sabe o que o código faz? Ainda não? Mais um pouco de código então:
E agora? Não?

Agora foi? Não?

Fácil de entender? Não? Vamos acrescentar o contexto que existe sobre esse código:

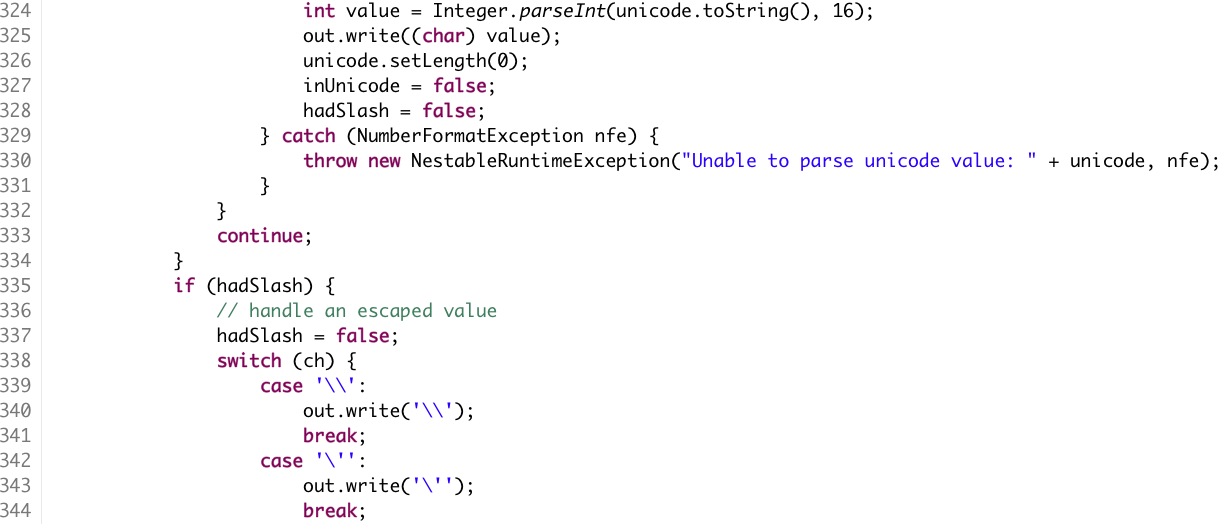
E agora, você conseguiu entender o código bem? Bom, isso facilitou um pouco. Agora você pelo menos sabe do que se trata. Mas você ainda não sabe se o que o código faz bate com o que está no comentário e no nome do método. Como saber isso? Lendo o código. Mas preste atenção no que aconteceu enquanto você lia o código.
Você provavelmente foi guardando os nomes das variáveis e o que elas faziam. Ao mesmo tempo foi mantendo na sua cabeça em
qual if você está, qual trecho muda o valor de hadSlash e coisas assim. Na terceira parte do código provavelmente você
já rolou a página pra baixo para ver qual era o meu ponto. E porque você fez isso? Porque você começou a ficar cansado de
tentar enteder o código. E uma das principais razões disso era a quantidade de informação que você tinha que manter na
sua cabeça enquanto lia. Essa sensação que você teve está fortemente associada à Estresse Cognitivo, um desgaste
causado por uso excessivo de capacidade mental para o qual não fomos treinados. Basicamente você fica mais cansado
mais rápido. Essa é uma razão que código curto parece melhor (digo parece porque afirmar qualquer coisa aqui é bem
difícil).
Densidade de Informação
Densidade de Informação é algo um pouco menos falado. Basicamente, a quantidade de informação útil (não barulho) e a redundância dessa informação afetam a nossa compreensão do texto (e consequentemente código). Este artigo do Shannon é bem interessante e bem mais profundo.
Então o que acontece quando temos baixa densidade de informação?
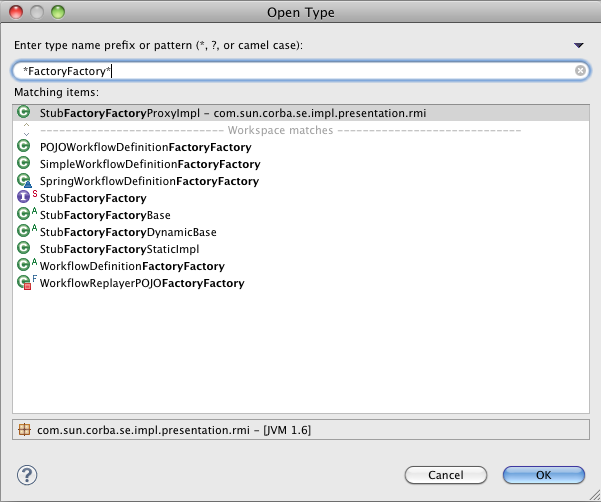
Temos muitas palavras e pouco significado. O que a StubFactoryFactoryProxyImpl faz? Difícil saber. Mas tudo bem,
usar corba como exemplo sempre é sacanagem. Vamos à um exemplo de código real:
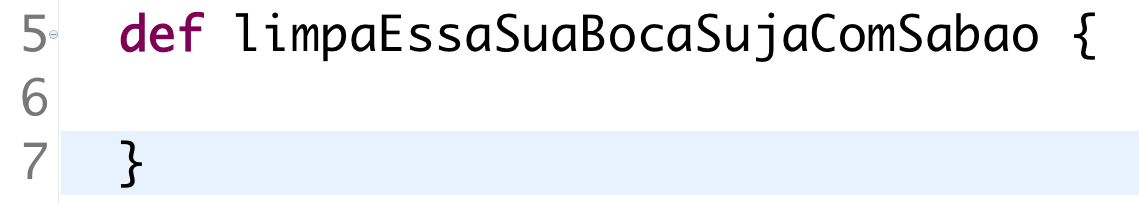
Esse é um nome de método real. Se você for bastante imaginativo, talvez entenda o que o método faz. Ele simplesmente remove palavras proibidas (palavrões e afins) de uma string. É um nome engraçado, mas que não informa o que faz.
Esse é um problema comum com Java. Os nomes de muita coisa não nos dão a informação que precisamos. Eles são barulho. Essa é uma das razões de dizerem que Java é verboso. Mas o problema não é Java (ok. Parte do problema é Java). O problema são as pessoas que programam em Java acharem isso normal e não se tocarem o quanto isso atrapalha o trabalho delas.
Mas também podemos ter problemas com densidade excessivamente alta de informação:

Novamente, esse é um código real, da trait TraversableLike de Scala. O nome foi bem escolhido (fica bem claro o objetivo do método), mas é meio complicato entender a implementação, mesmo que você programe Scala. Isso acontece porque existe muita coisa acontecendo naquelas 3 linhas de código.
Outro lugar em que isso acontece muito é com matemática:
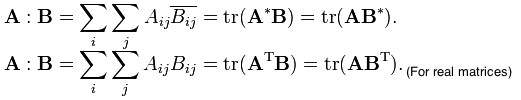
Olhando para a fórmula, é difícil dizer (à primeira vista) que ela calcula o produto escalar de dois vetores. Novamente, muita informação em pouco espaço. Cada símbolo possui um significado muito grande. É incrível para escrever, mas ler é um problema.
Conclusão
Esses quatro pontos são os que eu costumo prestar atenção quando escrevo código, porque para mim o equilibrio deles deixa o código mais legível e expressivo. Mas isso é muito subjetivo e com certeza não cobre todos os pontos que afetam legibilidade e afins.
O que vocês acham? A experiência de vocês é semelhante ou diverge muito da minha?
